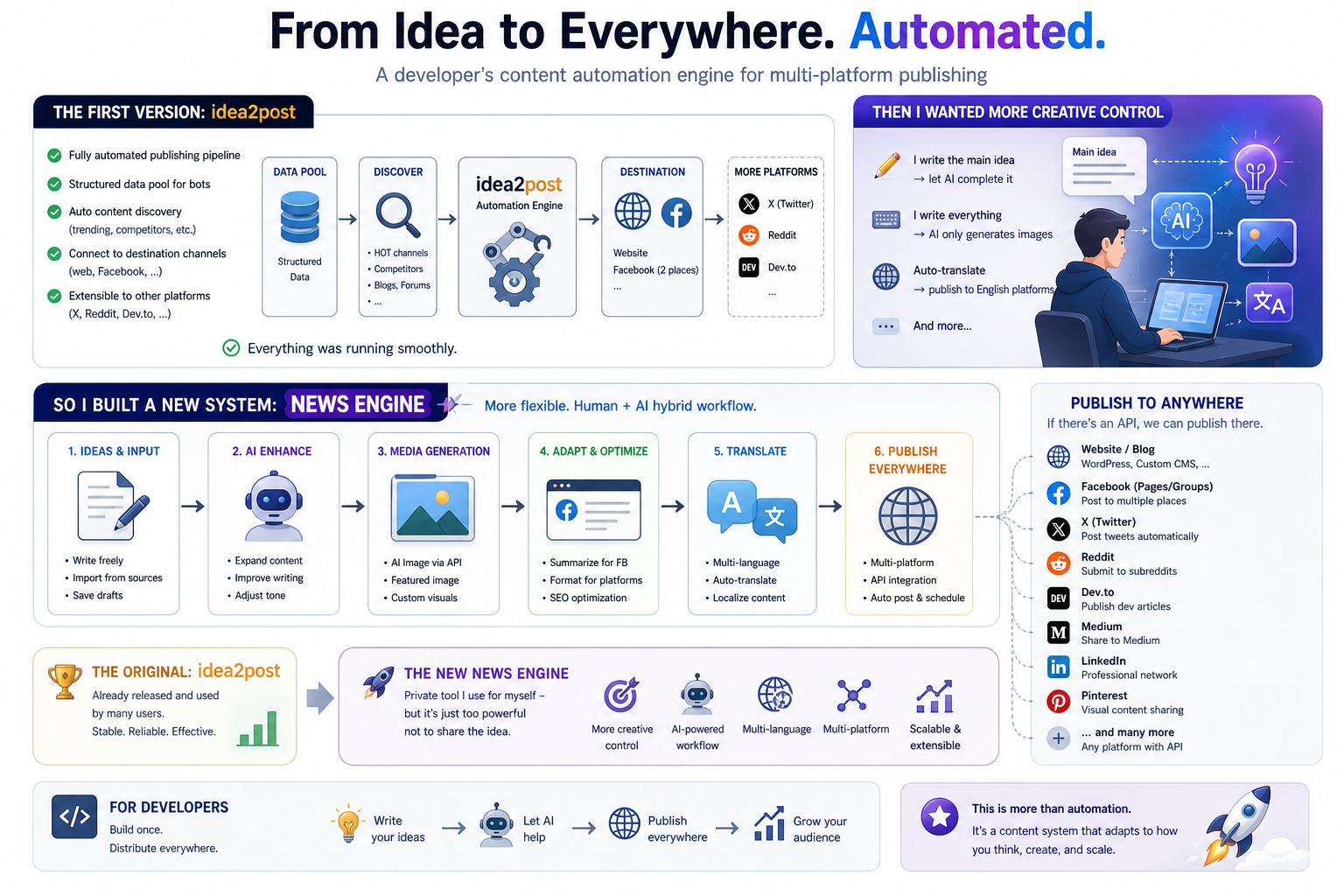
Every dev has built the same thing 50 times: a tiny FastAPI wrapper around a single LLM call. Different prompts, identical glue code. Today I shipped a CLI that generates that glue for you.
One command in:
prompt-to-api "generate a blog post"One file out: generate_blog_api.py — a complete, runnable FastAPI server with a POST /generate-blog endpoint. Run it, hit it with curl, you have a working API.
From thought to deployed endpoint in under a minute.
Repo: github.com/melyx-id/prompt-to-api · MIT.
Why this exists
If you've shipped any LLM-powered feature, you know the cycle:
- Write a prompt that works in ChatGPT.
- Stand up a FastAPI app.
- Wire it to the OpenAI SDK.
- Add Pydantic models, a system prompt constant, env var loading, error handling.
- Write a curl example for the README.
- Repeat tomorrow for the next prompt.
It's busywork. The interesting part — the prompt — takes 2 minutes. The boilerplate eats 30. prompt-to-api deletes that 30.
Install
git clone https://github.com/melyx-id/prompt-to-api.git
cd prompt-to-api
pip install -r requirements.txtOr as a CLI:
pip install -e .Python 3.9+. No API key required to generate — only to run the generated server.
30-second demo
$ prompt-to-api "generate a blog post"
✓ wrote generate_blog_api.py (3162 bytes)
✓ endpoint POST /generate-blog
Next steps:
pip install -r requirements.txt
export OPENAI_API_KEY=...
python generate_blog_api.pyNow run it:
$ export OPENAI_API_KEY=sk-...
$ python generate_blog_api.py
INFO: Uvicorn running on http://0.0.0.0:8000Call it:
curl -X POST http://localhost:8000/generate-blog \
-H 'Content-Type: application/json' \
-d '{"input":"why CRDTs matter for offline-first apps"}'Response:
{
"result": "CRDTs (conflict-free replicated data types) are...",
"model": "gpt-4o-mini",
"usage": {"prompt_tokens": 42, "completion_tokens": 380}
}Done. Auto-generated Swagger UI at /docs.
What's inside the generated file
Plain FastAPI + OpenAI SDK. No DSL, no surprises:
SYSTEM_PROMPT = """You are a focused API assistant. Generate a blog post. ..."""
@app.post("/generate-blog", response_model=GenerateResponse)
def generate_blog(req: GenerateRequest) -> GenerateResponse:
resp = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": req.input},
],
)
return GenerateResponse(result=resp.choices[0].message.content, ...)Read it. Edit it. Deploy it to Render / Fly / Lambda / a VPS — it's just one Python file.
Five APIs in five lines
prompt-to-api "generate a blog post" # /generate-blog
prompt-to-api "summarise news in 3 bullets" # /summarise-news
prompt-to-api "translate input text to Vietnamese" # /translate-vietnamese
prompt-to-api "classify the sentiment of a tweet" # /classify-sentiment-tweet
prompt-to-api "rewrite text to be more concise" # /rewrite-conciseFive files. Five running APIs. Less time than reading this paragraph.
Where to get a key
Generated APIs work with any OpenAI-compatible provider:
- AIGateCloud — free tier, automatic fallback across OpenAI / Anthropic / Gemini / DeepSeek / Groq. Default base URL of generated APIs. Recommended — you stop caring which provider is up.
- OpenAI — set
OPENAI_BASE_URL=https://api.openai.com/v1. - OpenRouter, Together, Groq, Ollama, vLLM — set the corresponding base URL.
Useful flags
| Flag | What it does |
|---|---|
-o, --out FILE | Override output filename. |
-e, --endpoint SLUG | Force a specific endpoint slug. |
-p, --port N | Default port for the generated server. |
--print | Print code to stdout instead of writing a file. |
--quiet | Suppress banner. |
Honest caveats
- One-shot generator. It doesn't re-design schemas after edits — by design. The output is just Python, edit it like any other file.
- One endpoint per file. Multiple endpoints? Run the CLI N times and merge routers.
- No streaming yet. SSE on the roadmap.
- No auth/ratelimit. Add
slowapior your gateway — not this tool's job.
Roadmap
--streamfor SSE responses.--smartmode that calls an LLM at generation time to design richer multi-field schemas.--deploy fly/--deploy vercelone-click handoff.- Output a
Dockerfile+render.yamlnext to the .py file.
Cheatsheet
# Setup
git clone https://github.com/melyx-id/prompt-to-api.git
cd prompt-to-api && pip install -r requirements.txt
# Generate
prompt-to-api "your prompt here"
# Run
export OPENAI_API_KEY=sk-...
python generate_*_api.py
# Done.Repo: github.com/melyx-id/prompt-to-api — MIT licensed. Stars and PRs welcome. Free LLM key with multi-provider fallback at aigatecloud.com.